
Wikipedia:Reference desk/Archives/Computing/2017 July 18
| Computing desk | ||
|---|---|---|
| < July 17 | << Jun | July | Aug >> | July 19 > |
| Welcome to the Wikipedia Computing Reference Desk Archives |
|---|
| The page you are currently viewing is a transcluded archive page. While you can leave answers for any questions shown below, please ask new questions on one of the current reference desk pages. |
July 18[edit]
Font[edit]
What font is this, in the lower part? The text is Russian. Judging by letters ц, щ and е, not Times New Roman. Thanks. Brandmeistertalk 15:02, 18 July 2017 (UTC)
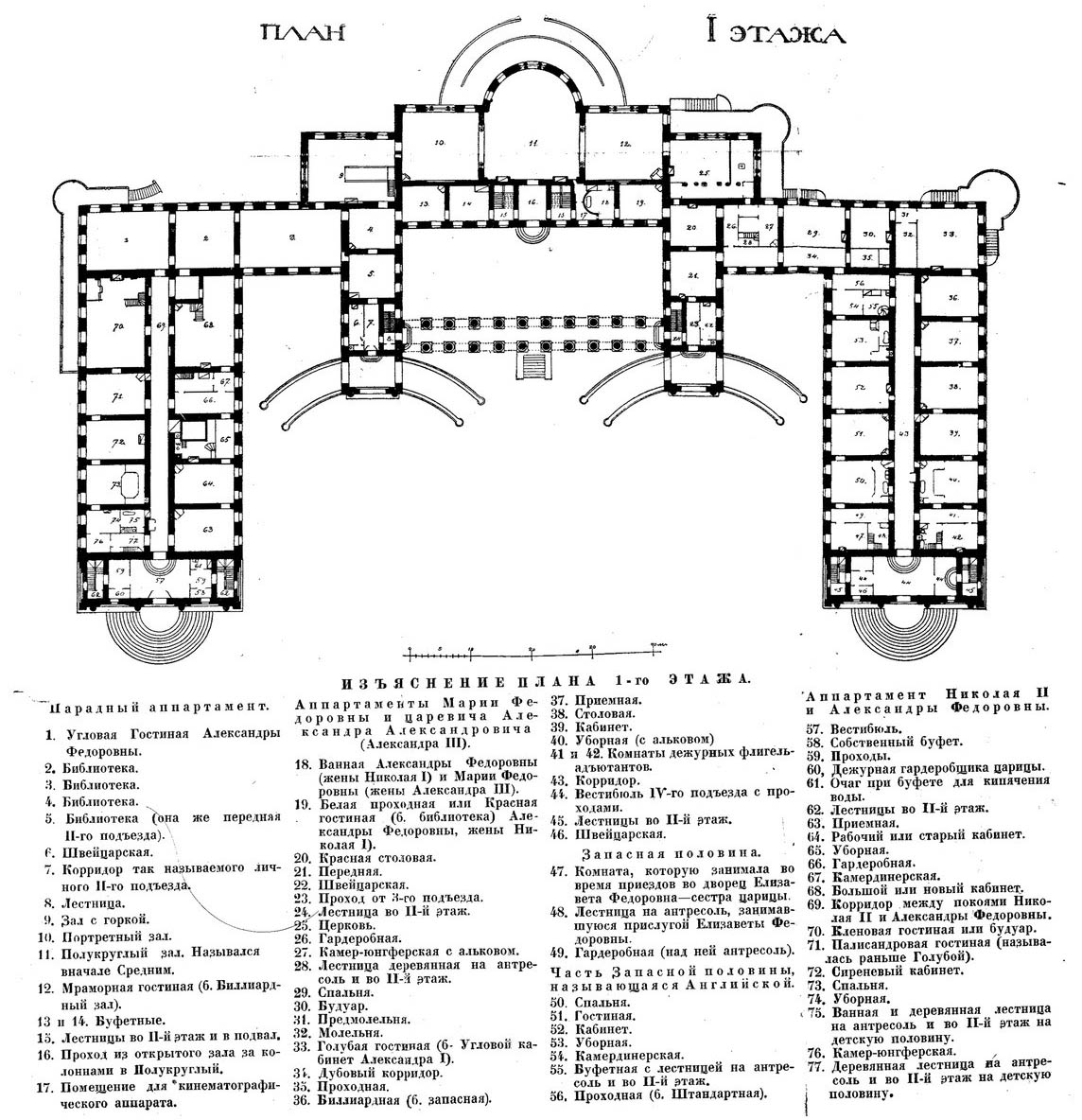{kind=link}
- You're not asking about the Cyrillic script used there, are you ? StuRat (talk) 15:09, 18 July 2017 (UTC)
- I looked in a book that had a font with ц in that shape and it said Akademicheskaya in the imprint. I don't know if that's the actual font in your example (I don't have an eye for fonts), but perhaps that'll help to narrow it down. 78.53.108.10 (talk) 15:29, 18 July 2017 (UTC)
- some Soviet technical standards for fonts. Assuming that's ALL the fonts there were (or at least the major families), then Akademicheskaya looks most like it indeed 78.53.108.10 (talk) 15:47, 18 July 2017 (UTC)
- Yep, much like that, thanks. Brandmeistertalk 17:43, 18 July 2017 (UTC)
BlueStack software[edit]
I possess and old version (unknown) of the software. I’m planning on to install it.
1) Will it update to the new version automatically? If so, how much MB could it be?
2) I’m planning on to use “Whatsapp” in it, via internet dongle (pay as you go modem), in PC, Will it work?
116.58.200.32 (talk) 17:21, 18 July 2017 (UTC)
- Why not use the web version of whatsapp instead of running an android emulator? Fr∧m∈Dr∧gtalk 17:25, 18 July 2017 (UTC)
- I viewed through, its actually giving me headache - I think you have to use the Smart Phone at the same time or something... My will is to use only the PC, not together with the Smart Phone. Please let me know if there is a possibility.
- Please help me with the emulator also:
- 1) I tried to install the version I possess, it directs installation in the C:\ drive, that is undesired. Does the new version display 'location selection option'? If no,
- 2) Is it possibile to install app(s) in different Drive?
- P.S: Is it fun playing phone games in PC?
- 43.245.122.94 (talk) 16:36, 19 July 2017 (UTC)
- Yes as the IP says whether Whatsapp Web or Whatsapp Desktop these both are simply retrieving the messages from the phone, so the phone needs to be working with internet access so it can receive the messages in the first pllace and needs to be accessible by the computer with the Web or Desktop client. Note however while you can I assume get Whatsapp working on an Android emulator, this means it will always be on the Android emulator. A single Whatsapp account can only function on one device at a time, so if you set it up on the Android emulator you can't use it on your phone except by using the web client to retrieve messages from the emulator or similar. It is possible to move your account to a new device but this isn't really something intended to be done regularly and you may also lose some of your history if you don't ensure the backup was synced right before you move. Nil Einne (talk) 05:10, 20 July 2017 (UTC)
- Could you help me with the installation please, I wish for everything to be installed in the D drive, including with the apps (probably in the E drive). A step by step guide is seeked. 116.58.204.130 (talk) 14:58, 20 July 2017 (UTC)
- I suggest you seek help elsewhere. I would note however that trying to install an old version would probably complicate things since people may be reluctant to dig up old versions to see/remember what their installer is like. I suggest you download the latest version rather than dicking around with old versions. Since you seemed to be willing to update to the new version anyway there's zero real advantage to starting with an old version. Note if you're trying to reduce data use that installing an old version and letting it update is not guaranteed to reduced data use. It may actually use more. Nil Einne (talk) 15:05, 20 July 2017 (UTC)
- Could you help me with the installation please, I wish for everything to be installed in the D drive, including with the apps (probably in the E drive). A step by step guide is seeked. 116.58.204.130 (talk) 14:58, 20 July 2017 (UTC)
- Yes as the IP says whether Whatsapp Web or Whatsapp Desktop these both are simply retrieving the messages from the phone, so the phone needs to be working with internet access so it can receive the messages in the first pllace and needs to be accessible by the computer with the Web or Desktop client. Note however while you can I assume get Whatsapp working on an Android emulator, this means it will always be on the Android emulator. A single Whatsapp account can only function on one device at a time, so if you set it up on the Android emulator you can't use it on your phone except by using the web client to retrieve messages from the emulator or similar. It is possible to move your account to a new device but this isn't really something intended to be done regularly and you may also lose some of your history if you don't ensure the backup was synced right before you move. Nil Einne (talk) 05:10, 20 July 2017 (UTC)
Smart Phone[edit]
Which software(s) could I use to converse with another human - with and without video calling facility - without a simcard's existence using Wifi (or any other methods could you specify) only...? 116.58.200.32 (talk) 17:21, 18 July 2017 (UTC)
Connecting via Bluetooth[edit]
My laptop doesn't have Bluetooth, so I bought a Asus bluetooth dongle and installed the software from the included CD. Now I'm trying to pair up my Bush SP-925 bluetooth speaker. However the speaker is not appearing in the list of available devices in the Settings panel.
What could I be doing wrong?
Rojomoke (talk) 17:37, 18 July 2017 (UTC)
- Try doing Wifi stuff with PC. Bluetooth dilemma are usually not reliable... 103.67.157.29 (talk) 18:19, 18 July 2017 (UTC)
- Can any other devices (e.g. your phone or tablet) "see" the speakers? On my JBL speakers you press a button to put it into pairing mode. 196.213.35.146 (talk) 06:08, 19 July 2017 (UTC)
Software[edit]
According to a person, "Connectify" supposedly allows you to connect your Smart Phone Wifi with the PC's WiFi, giving the ability to use PC internet facility on the Smart Phone.
Could you please direct me to an opensource source software that does as aforementioned, but with a 'pay as you go internet modem/dongle' (rather than an actual 'LAN system').
Basically, I wish to use my Smart Phone powered by the PC's 'pay as you go internet modem/dongle' via Wifi.
A step by step guide is required if possible of helping, I'm a 'novice' computer user...
103.67.156.12 (talk) 18:15, 18 July 2017 (UTC)
- If you want to turn your PC into a Wi-fi hot spot, you can use this software. Ruslik_Zero 18:27, 18 July 2017 (UTC)
- The internet is powered my the dongle! How do I integrate PC and Smart Phone's Wifi with the dongle? 103.67.158.48 (talk) 18:38, 18 July 2017 (UTC)
- AFAIK you're using Windows, so why do you want open source software to do this? Presuming your PC actually has wifi this is something Windows has supported since I think Vista or earlier. There's no need for additional software. It's obviously not open source but that's because you're using an OS which isn't open source. If your computer doesn't have wifi then you're going to need a wifi adapter or some other solution There's obviously no way your computer can magically share your computer's internet connection over wifi without wifi. Nominally it may be possible for the phone to use the computer's internet connection when connected to it, but that's going to require your phone is constantly connect and isn't something well supported (most people go in the other direction). 04:37, 20 July 2017 (UTC)
- What steps should I take?
- When I go on-line with using the dongle, a computer lookalike icon displays on the right bottom in the monitor screen next to the clock. Data movements are also displayed in the dongles software interface. Both of which meaning the internet is on. Then I turn on my Wifi. And then, how do I connect my Smart Phone to the PC, than use “Opera mini” or “Chrome”, “Google Play Store” on the Smart Phone (instead of using the internet on PC basically)? 43.245.121.141 (talk) 14:58, 20 July 2017 (UTC)
Google "spotlight" tracking news by IP or other factors?[edit]
Two days ago I looked up "crested butte" "metallurgical coal" on Google Search to respond to a Refdesk question. [3] My practice is to have Firefox clear all cookies whenever the browser is shut. Today I went news.google.com and their "spotlight" mentioned an item [4] which I looked at idly and turned out to be all about Crested Butte, a town I had never heard of before two days ago. (It also mentioned coal in passing) Is this a remarkable coincidence, or are they changing their search results to match previous searches by an IP?
This is of considerable importance to Wikipedians, because if the balance of search results turns out to be tuned to match our POV, we could end up in edit wars where both sides think they are "genuinely" expressing a "consensus" viewpoint about something in the media.
Given previous infiltration of Firefox (see "supercookie" ... wait, no, that doesn't mention a thing about it. I mean the back door cookie it didn't display several years ago) I cannot be confident about even this program, but I had no exceptions set, and when I quit and restarted and went back to Google just now the new cookie assigned was different than either of the two from the previous session. Wnt (talk) 18:58, 18 July 2017 (UTC)
- Do you know why that Q was asked two days ago ? If the OP saw a mention of them on a popular TV show, that could have made many people do those searches, pushing those items temporarily near the top of the heap, leading Google to spotlight that article which mentions them. StuRat (talk) 20:19, 18 July 2017 (UTC)
- That's definitely not it. The question was about met coal in the Illinois Basin -- I started looking for anthracite outside Pennsylvania, blundered onto a mention of the town, made that search, but did little further with it. I suppose an alternative explanation could be that the town is paying Google to toplist any search result having to do with it, or doing great SEO, but I doubt it. It doesn't seem like it's in the news a whole lot. Wnt (talk) 00:22, 19 July 2017 (UTC)
- Very many agents on the web may track you by all kinds of measures. Check out Panopticlick. You can politely ask web sites not to do so by setting the do-not-track header, but many will ignore that. Tools like the Electronic Frontier Foundation's Privacy Badger help a bit, as does surfing in incognito mode, but it's quite hard to become untrackable. --Stephan Schulz (talk) 10:57, 19 July 2017 (UTC)
- I appreciate this answer (I've been there before), but I should say in this case I'm less interested in privacy per se and more interested in what is known about what Google changes. Whatever I do, most Wikipedians working on articles will still be going to that site for an "unbiased" look at the web... to what degree, with what features, is this not going to be true? Wnt (talk) 11:02, 19 July 2017 (UTC)
- Very many agents on the web may track you by all kinds of measures. Check out Panopticlick. You can politely ask web sites not to do so by setting the do-not-track header, but many will ignore that. Tools like the Electronic Frontier Foundation's Privacy Badger help a bit, as does surfing in incognito mode, but it's quite hard to become untrackable. --Stephan Schulz (talk) 10:57, 19 July 2017 (UTC)
- A big part of DuckDuckGo's advertisement is that the same search will give the same result to any user. Google does not do this - depending on who you ask, they make informed decisions about what you probably want based on past data to deliver you a tailored search result, or they spy on you to sell your data to advertisers and sugarcoat it with free stuff.
- As to how Google knows that the Wikipedian that looked up "crested butte" and the person who went to news.google.com are the same person, see the answers above, but the main answer is still probably IP. Yes, your exact IP can change if dynamically attributed, but it is not a random IP among all possible ones. (Google will have a much easier time to tell you among 100 IP addresses than among a billion; Wikipedia vandals can get WP:RANGEBLOCKed).
- A free solution with a good efficiency-to-inconvenience ratio to impede IP tracking is to use the Tor browser, which is essentially a distributed VPN. (Of course, if you want to completely stop being IP-tracked, more drastic measures such as disabling Javascript are needed.) TigraanClick here to contact me 11:46, 19 July 2017 (UTC)
- Well if you're worried about Google tracking your searches bear in mind using Tor just means you're probably going give up on using Google since it's very difficult to use Google search with Tor given the number of exit nodes which are blocked. In the past most of these were simply Captcha blocks which were annoying but still allowed you to use it but there are now many hard blocks. So the question is whether you're happy with whoever you're using instead tracking your searches. BTW in terms of your point about edit wars, there's many reasons why Google searches are generally considered a very poor way of deciding anything on wikipedia. Even when they are used, this is only generally counting results, which still has many problems. Nil Einne (talk) 05:23, 20 July 2017 (UTC)
- I did not know Google blocked Tor exit nodes, but it makes sense considering their business model. (Of course, there are other search engines.)
- The theory is that whatever website you visit via Tor cannot trace back your IP from the data it receives. It can know you use Tor, but not who you are. Of course, if you want to defend against a sophisticated attacker, there are quite a lot of things to take into account beyond "download and use".
- I did not mention edit wars - the reference to WP:RANGEBLOCK was about the technical feasibility of attributing an IP address or address range to a single user, i.e. de-anonymizing an IP address. TigraanClick here to contact me 08:20, 20 July 2017 (UTC)
Sorry the edit war part was in reference to the OP's original point. I probably should have separated the messages but couldn't bt bothered. I know how Tor works. (Well at least beyond the basic level you are describing.)
But I don't understand what you mean by "business model". If you're suggesting that Google is blocking Tor exit nodes due to their desire to track end users, well there's zero evidence for that. All evidence points to it being to stop misuse of their site in ways that most would accept as misuse. Well some people seem to believe it's simply ordinary traffic from all the normal users of the exit nodes but I've always found this hard to believe. It's been going on for long enough that Google has had ample time to tweak their algorithms. And while I have heard their security division is a world of their own I find it hard to believe they would refuse to do so if it was truly just ordinary traffic. The most likely reason is is that it is what they consider misuse and this wouldn't be surprising, SEOers etc are not going to have any concerns about the harms of their misuse, they just choose whatever works for them. In any case I've never seen anyone remotely competent suggest it's anything more sinister than either of these options.
Although I'd note the OP was referring to Google News anyway. I'm not sure if Google News is generally blocked. I wouldn't be surprised if it normally isn't since most spammers, SEOers etc aren't interested in Google News results.
Google isn't the only one to cause problems for Tor users of course, plenty of other websites and services do so including Cloudfare. I mean heck even wikipedias generally block Tor exit nodes for editing. As I mentioned, there are other search engines and most of them including Bing have never seen the need to block Tor, but then the question becomes is there actually a reason to use Tor which depends significantly on what site you're now choosing to use, and what risks you're afraid of.
Nil Einne (talk) 15:27, 20 July 2017 (UTC)
- I was indeed suggesting that Google is blocking Tor exit nodes due to their desire to track end users (to generate more advertising revenue via targeted advertising). Yes, that is speculation on my part, but in the absence of an official Google statement about the block (a quick search turned up nothing) I would like to know what kind of misuse you have in mind before I consider your alternative hypothesis as more credible. I don't see how SEO is helped by Tor, for instance (if you are thinking about someone clicking through their own website repeatedly to make it go up the search result, Google could simply not count clicks from Tor exit nodes in their algorithm rather than forbidding any such clicks); email ports are blocked by Tor precisely to avoid spamming; en-wp forbids new users from editing via Tor nodes, for a Wikipedia-specific reason (user-generated content is the content of the website), but not all edition, and it does not restrict reading.
- Once you admit that Google tracks end users for targeted advertisement (need I really link?), there is nothing "sinister" is banning those who don't play ball. Google has to pay the bills, and users are happier volunteering their data rather than their money. Google blocking Tor is the equivalent of newspaper websites blocking users of ad-blockers, which I have heard described as inconvenient or inefficient, but not yet as immoral. TigraanClick here to contact me 15:50, 20 July 2017 (UTC)
- Except no one remotely credible, which let's remember includes even Tor developers [5] believes anything remotely like that. Admittedly Tor developers are one of the ones who still seem to believe it's because if misidentification rather than intentional identification of abuse. Only wacky conspiracy theorists believe it. And Google only blocks some of them and extremely haphazardly (sometimes it works sometimes it doesn't sometimes it requires a Captcha sometimes multiple and sometimes at least in the past it just seems to get stuck in Captcha loops and sometimes you solve a Captcha only to be then told you're permanently blocked and of course the Captcha where is does work usually stays for a while per session and it also seems to depend possibly on the specific search terms and the Google subdomain and many others things). And most people just don't use Google rather than not using Tor because the people who've chosen to use Tor generally have a good enough reason that they'll keep using it whereas while they may prefer to use Google it isn't required. And this is actually likely a bigger risk to Google than the tiny number of people who do use Tor, since they may find that some alternative actually works better for them and it's likely most Tor. You also came up with a fairly wacky misuse which as you yourself acknowledge makes no sense. The way people are far more likely to misuse Google is by making automated queries to try and help them figure out how to improve their rankings, using searches for building their own database etc etc. (Probably a lot of these aren't actually achieving anything fruitful, but SEOers etc often don't care.) After all Google's explaination for why they're blocking you says similar stuff [6] And as for the other reasons, I know all that it's what I already said (well I didn't specifically mention email blocking although I did mention Cloudfare who of course also say it's due to genuine misuse [7]). And it precisely correlates with the Google experience. People block Tor precisely because of misuse which they believe causes them significant harm and there's zero evidence and no reason to believe Google really gives a fuck about not being able to track Tor users, but good reason to think and plenty of indirect evidence that people do frequently misuse Google by making automated queries for their own benefit which Google understandably does not like. Let's not forget the automatic blocking predated Tor blocking and still happens all the time to IPs which misuse Google in such ways which aren't Tor exit nodes. Misusers of course, whether of Google or other services, are always looking for ways to be able to carry out their misuse either without being blocked or without being tracked down, and don't give a flying flip who they affect and Tor is often cheaper than a botnet or digging through open proxies and for Google at least, probably works well enough that it's still useful. Nil Einne (talk) 18:03, 21 July 2017 (UTC)
- I don't really understand why you want a Google official statement. If you believe in wacky conspiracy theories as you do, then Google could just be lying. How is an official statement any more believable than what Google tells you when they block you? It makes no sense. It's not like an official statement that "We block certain Tor exit nodes and limit others because of what appear to be automated queries originating from there" is less likely to be a lie than the pages you get when you are blocked. I mean if Google is going to use their system which blocks automated queries to block you for using Tor exit nodes because they want to track you, then they might as well just make an official statement to the effect that the block is for automated queries if it has any benefit. I mean besides the fact they're using the system for blocking automated queries, there's also the fact it's as I said so variable so clearly whatever they're doing they're either basing it on real behaviour or if they are intentionally blocking Tor they're doing it haphazardly to try and trick people into thinking it isn't just a simple Tor block which they could obviously easily do given that all exit nodes are published. I don't think they bothered because most wacky conspiracy theorists are at least consistent. If they aren't going to believe the pages that Google sends them when blocking them, then they aren't going to believe an official statement. For everyone else, they accept what the block pages say although as I mentioned, one open question is whether it's misidentification (as I said I find it unlikely after all this time) or correct identification of genuine misuse. Nil Einne (talk) 18:10, 21 July 2017 (UTC)
P.S. Another point on how silly it all is is that we know Google has fairly sophisticated tracking systems [8] and are also in a position of great privilege and many users of Tor do dumb things. There's a good chance Google would actually be getting more info by simply allowing those Tor users to do searches. Especially since they do sometimes allow them to login to their accounts over Tor [9]. (And again the fact that account login and usage is intermittent indicates either that they're making ab effort to hide what they're doing, or it's simply a complicated interaction between automated security systems and traffic that's deteced.) Since as I said, in most cases people are just going to settle for some other search engine when Google doesn't work rather than not use Tor. There may be a tiny number of people who would use Tor full time were it not for the Google block but it's likely this number is very tiny especially since there is probably stuff like IXquick, and there used to be Disconnect. And yes a number of these services access to Google was lost, but again even they don't come up with wacky conspiracies about it being because Google wants to force people to being tracked. Maybe it's because they believe it but don't want to risk alienating Google since they may one day change their mind, or maybe it's because they recognise Google is a complicated company who after all have allowed Tor and similar projects to be part of the Summer (actually Winter) of code and helped or supported them in other ways [/tor.stackexchange.com/questions/313/does-google-know-that-i-am-using-tor-browser] [10] [11] to put some overreaching Google to track people into all their behaviour is silly since Google is large company and not a monolith but rather has a lot of different people making a lot of different decisions for a lot of different reasons.
P.P.S. I'm reminded of those who are convinced Tor is a con since the US government including the NSA was involved.
P.P.P.S. I'm not saying that Google's blocks particularly the hard ones are necessary. Actually my comment above about the security division being a world of their own relates to some comment I believe I read once from a Google staffer who IIRC said multiple people had tried to get them to relax the Tor blocks but it was very difficult because the security division were allowed to do whatever they wanted because they had convinced management it was necessary and working. Unfortunately I've spent way too long already but can't find this comment again. Either way though the point is that there's no real reason to think this isn't because of what Google perceives as genuine misuse from automated queries as they say it is, whether the actual negative effects to Google from this are really worth the bother to their genuine end users. I'd note that the Cloudfare block mentions that genuine abuse seen by Google is also why people get the worse ReCaptchas. Actually their way of improving things was IMO a decent solution. Somehow though, I doubt Google are going to force their security division to use Tor so they can see how annoying it is and try and see if their are ways they can achieve their goals with less pain, and also whether their goals are always necessary which is unfortunate but oh well.
P.P.P.P.S. Some of the stuff I read [12] [13] while trying to find the post I thought I read from a Google staffer reminded me of another wacky conspiracy theory, that Google intentionally serves ReCaptcha's even when they're sure there is no abuse simply to to get the work. That seems to often arise amongst other reasons, because people confuse the fact that because Captcha's can't block all bots, it means they are useless which demonstrates the sort of limited thinking that seems to give rise to these wacky conspiracy theories. They don't have to block all bots, just enough that whoever implemented it feels it's worth it. This doesn't mean that Captchas are always the best solution, well implemented or get the balance between blocking bots and inconveniencing end users right, as one of the comments said they often don't. But that's because the developers aren't willing to spend the necessary effort and/or haven't analysed the situation well enough and/or isn't caring enough about their end users. And yes to avoid future dispute, there are probably cases when Captcha are completely useless and of course particularly for small sites, the person may just implement it without any testing. Still getting back to my earlier point, it's clearly flawed to think Captchas never achieve anything just because they can be broken and there's no real reason to think Google intentionally served ReCaptchas for the work as opposed to, flawed or not, a genuine attempt to stop misuse.
Nil Einne (talk) 19:34, 21 July 2017 (UTC)
- (EC with below) As a final comment since I've definitely spent way too much time on this now, just to be clear, I'm not in any way suggesting Google doesn't have a desire to track their users as much as possible to use the data as part of their business. They clearly do. But that's a far cry from thinking every action they ever do is related to this goal. Especially when there is plenty of other evidence, including from Google itself suggesting it isn't the goal in some specific instance. As I said, Google could be lying when they tell you you're being blocked for automated queries, but an official statement isn't going to resolve that. If you want to believe the wacky conspiracy theory that they actually care enough about their inability to track the tiny number of users using Tor, despite the fact they could probably track them better if they didn't block them and most of them aren't going to stop using Tor simply because of the block then go ahead. Meanwhile the rest of us in the real world will go on believing what makes the most sense and so every other RS (as I've presented) including the Tor developers say, namely that it's simply because Google is either accidentally misidentifying or correctly identifying people abusing Google using Tor. Just as they abuse a lot of other services using Tor. Except for Bing etc since well no one can be bothered to abuse that (much). Nil Einne (talk) 20:05, 21 July 2017 (UTC)
- I don't really understand why you want a Google official statement. If you believe in wacky conspiracy theories as you do, then Google could just be lying. How is an official statement any more believable than what Google tells you when they block you? It makes no sense. It's not like an official statement that "We block certain Tor exit nodes and limit others because of what appear to be automated queries originating from there" is less likely to be a lie than the pages you get when you are blocked. I mean if Google is going to use their system which blocks automated queries to block you for using Tor exit nodes because they want to track you, then they might as well just make an official statement to the effect that the block is for automated queries if it has any benefit. I mean besides the fact they're using the system for blocking automated queries, there's also the fact it's as I said so variable so clearly whatever they're doing they're either basing it on real behaviour or if they are intentionally blocking Tor they're doing it haphazardly to try and trick people into thinking it isn't just a simple Tor block which they could obviously easily do given that all exit nodes are published. I don't think they bothered because most wacky conspiracy theorists are at least consistent. If they aren't going to believe the pages that Google sends them when blocking them, then they aren't going to believe an official statement. For everyone else, they accept what the block pages say although as I mentioned, one open question is whether it's misidentification (as I said I find it unlikely after all this time) or correct identification of genuine misuse. Nil Einne (talk) 18:10, 21 July 2017 (UTC)
- Except no one remotely credible, which let's remember includes even Tor developers [5] believes anything remotely like that. Admittedly Tor developers are one of the ones who still seem to believe it's because if misidentification rather than intentional identification of abuse. Only wacky conspiracy theorists believe it. And Google only blocks some of them and extremely haphazardly (sometimes it works sometimes it doesn't sometimes it requires a Captcha sometimes multiple and sometimes at least in the past it just seems to get stuck in Captcha loops and sometimes you solve a Captcha only to be then told you're permanently blocked and of course the Captcha where is does work usually stays for a while per session and it also seems to depend possibly on the specific search terms and the Google subdomain and many others things). And most people just don't use Google rather than not using Tor because the people who've chosen to use Tor generally have a good enough reason that they'll keep using it whereas while they may prefer to use Google it isn't required. And this is actually likely a bigger risk to Google than the tiny number of people who do use Tor, since they may find that some alternative actually works better for them and it's likely most Tor. You also came up with a fairly wacky misuse which as you yourself acknowledge makes no sense. The way people are far more likely to misuse Google is by making automated queries to try and help them figure out how to improve their rankings, using searches for building their own database etc etc. (Probably a lot of these aren't actually achieving anything fruitful, but SEOers etc often don't care.) After all Google's explaination for why they're blocking you says similar stuff [6] And as for the other reasons, I know all that it's what I already said (well I didn't specifically mention email blocking although I did mention Cloudfare who of course also say it's due to genuine misuse [7]). And it precisely correlates with the Google experience. People block Tor precisely because of misuse which they believe causes them significant harm and there's zero evidence and no reason to believe Google really gives a fuck about not being able to track Tor users, but good reason to think and plenty of indirect evidence that people do frequently misuse Google by making automated queries for their own benefit which Google understandably does not like. Let's not forget the automatic blocking predated Tor blocking and still happens all the time to IPs which misuse Google in such ways which aren't Tor exit nodes. Misusers of course, whether of Google or other services, are always looking for ways to be able to carry out their misuse either without being blocked or without being tracked down, and don't give a flying flip who they affect and Tor is often cheaper than a botnet or digging through open proxies and for Google at least, probably works well enough that it's still useful. Nil Einne (talk) 18:03, 21 July 2017 (UTC)
- Well if you're worried about Google tracking your searches bear in mind using Tor just means you're probably going give up on using Google since it's very difficult to use Google search with Tor given the number of exit nodes which are blocked. In the past most of these were simply Captcha blocks which were annoying but still allowed you to use it but there are now many hard blocks. So the question is whether you're happy with whoever you're using instead tracking your searches. BTW in terms of your point about edit wars, there's many reasons why Google searches are generally considered a very poor way of deciding anything on wikipedia. Even when they are used, this is only generally counting results, which still has many problems. Nil Einne (talk) 05:23, 20 July 2017 (UTC)
(edit conflict)Had I understood sooner that the Tor-blocking was not a Tor-specific thing but based on a large rate of queries originating from the same endpoint, I wouldn't have thought up a "wacky conspiracy theory
" (BTW, was that language really justified?). I did not have a Tor install to see for myself the error message, and your earlier posts are not exactly illuminating about it. And had you given the CloudFlare link earlier, I would have had something else than your word for "traffic from Tor nodes is made mostly of abuse" (though their "94% of Tor requests are malicious" figure screams to have a look at the corresponding figure for non-Tor requests, I will readily assume they have done the complete homework). TigraanClick here to contact me 19:40, 21 July 2017 (UTC)
- If you don't understand, you should ask rather than coming up with wacky conspiracy theories. Or you could just search. As I demonstrated there are many, many, many, many results talking about the block for automated queries which affects Tor which can be found with, you guessed it, a 10 second Google search (which I guess you can since you clearly aren't using Tor). I didn't bother to give the CloudFare link because it didn't seem necessary. It was besides the point since we were discussing Google blocks not CloudFare ones. The Cloudfare point was just to demonstrate that Google weren't the only one. If you wanted for evidence that CloudFare was blocking for abuse as I said in my second post, you could have either asked for an RS or guess what, again done a 10 second Google search before you came up with wacky conspiracy theories after I pointed out the Cloudfare block. Frankly you probably shouldn't be talking about Tor too much if you weren't aware of either the Google block or Cloudfare block since you don't seem to know much about it. And you definitely shouldn't be coming up with wacky conspiracy theories, especially after someone has already told you of these and the stated reasons even if the results of a 10 second search weren't presented since they weren't asked for and I didn't feel they were necessary. (Remember I wasn't responding to a question, but first made a simple slightly facetious point, and then when what I perceived as incorrect information, I simply pointed out why it was wrong. Yes I didn't provide sources, mostly because I assumed someone who was talking about this crap would already know what I was talking about, or would search for refs themselves or at least ask before proceeding with their wacky misinformation. Once it became clear you had no idea what you were talking about but were still going to spread misinformation, I did present the sources and further explanation spending a lot of my time in doing so. Something which could have been avoided if you had avoided (doing what I really, really hate with a passion namely) spreading misinformation and instead asked for sources if you had doubts on something you knew next to nothing about.) As I said, a large number of services block or limit Tor and most of their say it's because of abuse which makes sense since as I already said and really anyone discussing these things should realised. And again you can find out about this from a 10 second Google search [14] [15] presuming you aren't using Tor. And it makes sense since whatever the percentage, abusers are obviously going to want to use Tor if they can and the nature of Tor makes it difficult to stop them. I mean heck IIRC even Facebook requires a Captcha for logins on their hidden service unlike the normal internet where it's generally only required after some failures for the obvious reason that they have no real way of knowing whether it's your first or 10^10 try on Tor. Nil Einne (talk) 20:08, 21 July 2017 (UTC)
- And yes the term was justified and your response perfectly demonstrated it was. You appear to have zero evidence or reason to believe it was the case other than some monolithic view of how Google operates and an apparent serious misunderstanding of what the blocks were even like or how they work despite the fact this information could have been found with a 10 second Google search, and is discussed on Tor's on site. (Something I did consider linking in my second reply, but decided not to bother since it's such basic info and I already mentioned what most people believe and again a 10 second Google search will find that and much, much more.) Coming up with weird ideas based on a strange world view and a lack of basic understanding of what your even talking about, despite the fact a 10 second Google search would correct some of these serious misconceptions on your part is the epitome of wacky conspiracy theories. (P.S. If you've never noticed, I normally use the term "internet search" and I'm sure other search engines would work fine here too. I'm using Google search here for obvious facetious reasons.) The fact that you're not so far gone as many extreme conspiracy theorists are, that you refuse to accept what you read is good, but isn't justification for spreading wacky conspiracy theories here in the first place. And yes I am IMO justifiably annoyed because as I said, I hate misinformation and dislike having to spent so much time to demonstrate why something is misinformation when it could have been avoided if you'd simply done some basic research before replying. Especially since in this case I already gave the basics after I first detected possible misinformation. And yes I probably didn't need quite so much information but I dislike getting involved in lengthy back and forths so once it became clear where this was headed, I wanted to ensure I had all the key information just in case there was continued dispute. Especially since what you said made me assume you understood the basics (and so this was a wider dispute) but you apparently don't (and so it was actually a simply dispute based on a lack of basic research before spreading misinformation). Okay maybe misinformation is too strong a word but information which is supported by basically nothing is a lengthy thing to say. Nil Einne (talk) 20:27, 21 July 2017 (UTC)
- (edit conflict) FTR, I had searched "why does Google block Tor" and other similar queries and found nothing (unless we count forum posts according to which it's the government' fault).
- Providing sources for non-trivial assertions (e.g.
All evidence points to it being to stop misuse of their site in ways that most would accept as misuse
) is a basic rule of the refdesk, in part to avoid starting completely avoidable flamewars such as this one. Even if you had assumed some stuff should have been obvious to me, other people are reading. Please also notice that I clearly labelled my speculation as speculation,so I do not think calling itspread[ing] misinformation
was fair. - Anyways, I doubt anything productive will come out of this. Please accept my apologies for any wrongful behavior on my part. If you agree to let the whole thing go, maybe you could hat this subthread. TigraanClick here to contact me 20:35, 21 July 2017 (UTC)
- And yes the term was justified and your response perfectly demonstrated it was. You appear to have zero evidence or reason to believe it was the case other than some monolithic view of how Google operates and an apparent serious misunderstanding of what the blocks were even like or how they work despite the fact this information could have been found with a 10 second Google search, and is discussed on Tor's on site. (Something I did consider linking in my second reply, but decided not to bother since it's such basic info and I already mentioned what most people believe and again a 10 second Google search will find that and much, much more.) Coming up with weird ideas based on a strange world view and a lack of basic understanding of what your even talking about, despite the fact a 10 second Google search would correct some of these serious misconceptions on your part is the epitome of wacky conspiracy theories. (P.S. If you've never noticed, I normally use the term "internet search" and I'm sure other search engines would work fine here too. I'm using Google search here for obvious facetious reasons.) The fact that you're not so far gone as many extreme conspiracy theorists are, that you refuse to accept what you read is good, but isn't justification for spreading wacky conspiracy theories here in the first place. And yes I am IMO justifiably annoyed because as I said, I hate misinformation and dislike having to spent so much time to demonstrate why something is misinformation when it could have been avoided if you'd simply done some basic research before replying. Especially since in this case I already gave the basics after I first detected possible misinformation. And yes I probably didn't need quite so much information but I dislike getting involved in lengthy back and forths so once it became clear where this was headed, I wanted to ensure I had all the key information just in case there was continued dispute. Especially since what you said made me assume you understood the basics (and so this was a wider dispute) but you apparently don't (and so it was actually a simply dispute based on a lack of basic research before spreading misinformation). Okay maybe misinformation is too strong a word but information which is supported by basically nothing is a lengthy thing to say. Nil Einne (talk) 20:27, 21 July 2017 (UTC)
POSIX: Expand stack space with anonymous mmap?[edit]
In POSIX environments, can a program's main thread effectively expand its stack space by allocating adjacent addresses with an anonymous mmap (even when one has to test which way the stack grows), so that the stack will "overflow" into the mmap rather than into invalid addresses? If so, what notable open-source software -- if any -- uses this technique? NeonMerlin 22:59, 18 July 2017 (UTC)
- Well, I did manage this:
// compile this with -DBIG_STACK to enable a large mmap() allocated stack - without that,
// abuse_stack() will allocate more than the rlimit standard 8MB of stack, and the
// program will SEGV.
#include <alloca.h>
#include <stdio.h>
#include <sys/mman.h>
#include <ucontext.h>
#define MYSTACK_SIZE (1024 * 1024 * 30)
static void abuse_stack() {
for (int i = 0; i < 20; i++) {
printf("%d\n", i);
fflush(stdout);
void *p = alloca(1024 * 1024);
}
}
int main() {
#ifdef BIG_STACK
char *mystack = mmap(0, MYSTACK_SIZE,
PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS,
-1, 0);
static ucontext_t ctx[2];
getcontext(&ctx[1]);
ctx[1].uc_stack.ss_sp = mystack;
ctx[1].uc_stack.ss_size = MYSTACK_SIZE;
ctx[1].uc_link = &ctx[0];
makecontext(&ctx[1], abuse_stack, 0);
swapcontext(&ctx[0], &ctx[1]);
#else
abuse_stack();
#endif
}
- which uses the (deleted!) POSIX call swapcontext to change the stack pointer of the current thread; I guess one could just do it manually with assembly to set $SP directly. The context API was removed from POSIX in favour of pthreads, where pthread_attr_setstack is its analog. Using that would fail (as far as I know) your requirement to change the program's main thread's stack, but I don't see a practical reason for that requirement. -- Finlay McWalter··–·Talk 15:18, 19 July 2017 (UTC)